
Data Mesh and Event-Driven Architecture Don’t Remove Central Governance
Modern data architectures promise speed and autonomy—but without centralized semantics and governance, “distributed” quickly becomes “unmanageable.”
Modern data architectures promise speed and autonomy—but without centralized semantics and governance, “distributed” quickly becomes “unmanageable.”
Enterprises are embracing Data Mesh and Event-Driven Architecture (EDA) to escape central delivery bottlenecks. The promise is attractive: distribute ownership to domains, split work into microservices, publish events, and move faster with smaller teams. Early results often look like a win—until the organization needs reliable cross-domain reporting, auditability, or scalable analytics and AI.
Then a different reality appears: complexity wasn’t eliminated, it was redistributed—into semantics, interoperability, and operational reliability. Without a shared foundation, “modern architecture” becomes an ecosystem of incompatible definitions, uncertain lineage, and fragile integrations.
The more distributed your architecture becomes, the more centralized your semantics and governance must be.
This is not a call for committee-driven approvals or a return to a monolithic warehouse team. It is a call to treat semantics and governance as infrastructure—the backbone that enables autonomy without sacrificing coherence, reliability, or compliance.
The Core Tension: Decentralized Delivery vs. Shared Meaning
Data Mesh and EDA solve real pain:
- Central data teams can’t keep up with demand.
- Domains want autonomy and faster iteration cycles.
- Microservices encourage independent deployments and bounded contexts.
But data is not only a technical output—it is also an enterprise language. Microservices reduce coupling in code; they do not reduce the need to coordinate meaning across boundaries. If “Meter,” “Customer,” “Asset,” “Order,” or “Revenue” drift across teams, the enterprise loses the ability to reason about itself.
So the real problem becomes:
How do we decentralize execution while centralizing the rules that preserve coherence?
Data Mesh: Domain Ownership Without Shared Rules Turns Into Entropy
Data Mesh is often simplified to “domains own data.” In the original framing, decentralization is paired with federated computational governance: global rules, automated enforcement, and domain autonomy inside those rules.
When governance is weak, outcomes are predictable:
- Multiple definitions for the same entities and KPIs.
- Incompatible identifiers and code sets across domains.
- Downstream “fixes” and hidden transformations that become permanent.
- Unclear ownership when quality breaks.
- Missing lineage, turning investigations into guesswork.
In short: the mesh can scale delivery, but it also scales the consequences of semantic drift. If you decentralize production without centralizing meaning, you don’t get agility—you get fragmentation.
Event-Driven Architecture: Events Scale Integration—and Semantic Ambiguity
EDA enables loose coupling and real-time propagation, but it also turns event streams into enterprise-wide interfaces. Every event schema is an API for meaning.
If event publishing is treated as “just JSON,” teams get:
- Event type proliferation with overlapping intent.
- Schema drift and accidental breaking changes.
- Consumer-specific workarounds and brittle mappings that re-create coupling downstream.
EDA doesn’t reduce the need for shared semantics—it amplifies it, because meaning is distributed through events at volume and reused in many places. The more consumers you have, the more expensive ambiguity becomes.
Why Large Enterprises Drift Toward “Custom Microservices Everywhere”
The move away from enterprise ELT/BI tooling is rarely only technical. It is often driven by incentives and budget mechanics:
1) Visible license costs vs. invisible fragmentation costs
Licenses are crisp line items; reconciliation effort, duplicated pipelines, KPI disputes, incidents, and compliance remediation are distributed across budgets.
2) Autonomy as an organizational accelerator
Domains want to ship on their own cadence and escape central release trains.
3) Talent market realities
It may be easier to staff mid-level backend engineers than senior data modelers, governance specialists, and platform engineers—so architecture drifts toward what can be built with the available profile.
4) AI expectations
Decomposed work looks “agent-friendly.” But AI accelerates production, not coherence. Without shared semantics and enforceable contracts, it can generate incompatible artifacts faster—turning “speed” into “faster divergence.”
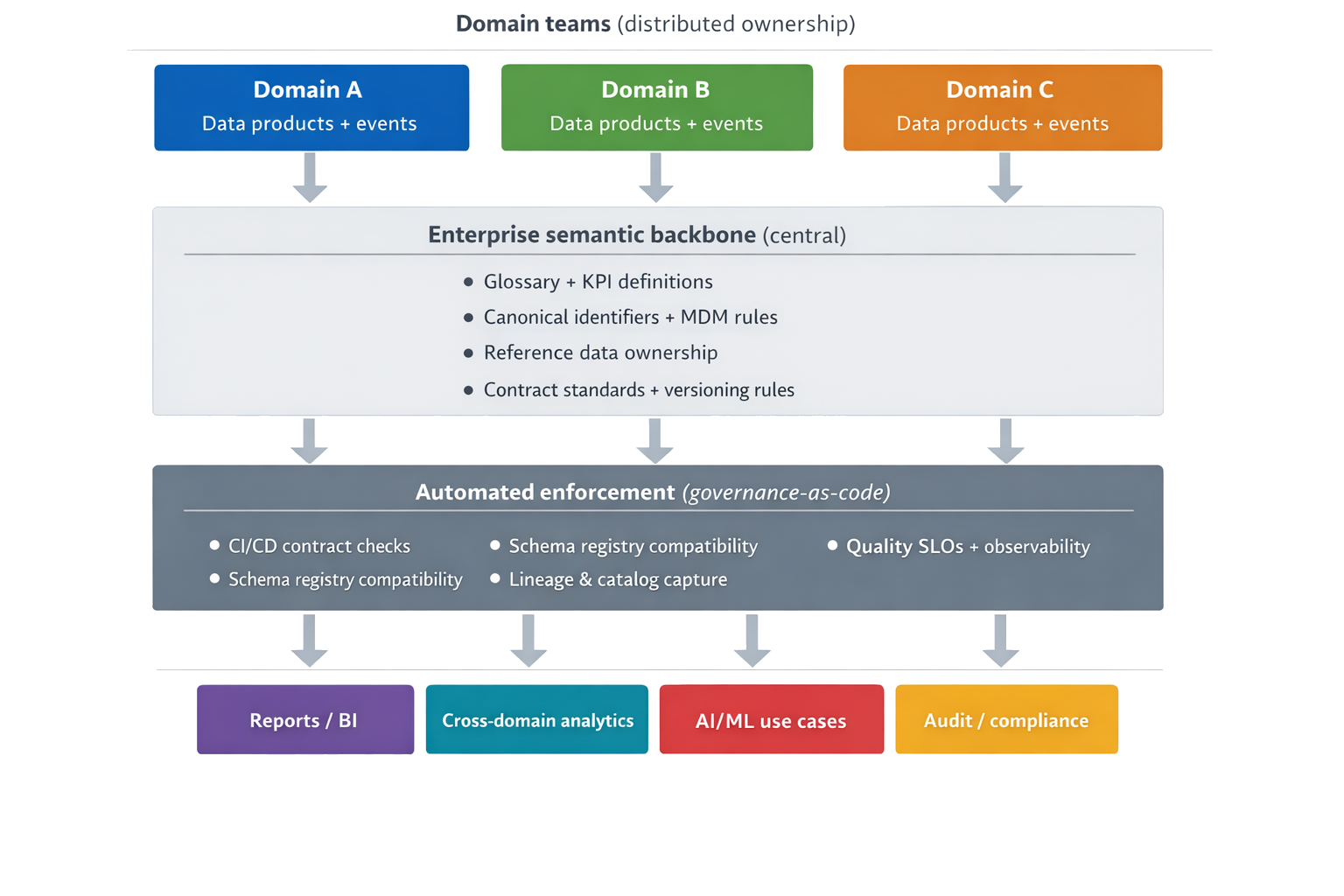
The Semantic Backbone: Enterprise Data Model as a Shared Contract
A modern Enterprise Data Model (EDM) should not be a static diagram—or a single physical schema imposed on everyone. It is most effective as a semantic backbone:
- clear definitions (glossary),
- canonical identifiers for core entities,
- reference data strategy (codes, statuses, hierarchies),
- mappings that make domain variation explicit rather than accidental.
To work, the semantic backbone must be:
- understandable to business stakeholders (definitions + examples),
- usable by developers (contracts, schema rules, versioning),
- operational (tied to catalog, lineage, quality checks, and access policies).
If semantics live only in slides, they won’t change outcomes.
Diagram: distributed execution, centralized meaning (semantic backbone + automated enforcement)
Case Vignette: “We Replaced the Platform, but Lost the Map”
A large energy enterprise (roughly eight business domains) ran a classic centralized setup: a corporate data warehouse with enterprise ELT/BI and a central reporting layer. Delivery was slow, largely because the solution had been built by an external integrator and handed over with limited documentation—knowledge transfer became the bottleneck.
To reduce license dependency and regain control, the organization began shifting toward custom components. Domain teams started replacing parts of the pipeline and reporting ecosystem with custom Java APIs and service-specific “mini databases.” Integration became increasingly event-centric (Kafka alongside existing integration middleware). The migration progressed faster than the enterprise semantic foundation.
The most expensive problem was not broken code—it was broken traceability. With no enterprise glossary, no master data strategy, no reference data ownership, and no lineage/catalog or reliability SLOs, it became difficult to answer basic questions such as: Which system is authoritative for this metric? Where does this number come from today?
The issue surfaced sharply during an annual report on average energy consumption per meter. The organization was effectively running two parallel pipelines:
- daily figures consumed from the legacy BI path, and
- yearly aggregation produced through the newer microservice/event path.
Because the data models differed, synchronization lags varied, and there was no enterprise-level map of data flows and entity definitions, the report produced missing or unexpected results. A customer inquiry triggered the investigation. The breakthrough came only after replaying historical data and comparing outputs to isolate where the two pipelines diverged.
In practice, the investigation required coordination across two value-stream development teams (microservices) plus a DBA, middleware support, and the platform team—a cross-functional effort driven largely by elimination rather than by impact analysis. Without lineage, teams spent weeks determining whether the discrepancy originated upstream, in transformations, or in the reporting layer. The correction effort contributed to an estimated two-month delay in delivering the final annual report.
Lesson: replacing enterprise tooling can reduce visible platform dependency, but without a shared semantic backbone and operational governance, it also removes the “map” of what data means and how it moves—turning discrepancies into costly archaeology.
What Must Be Centralized vs. What Can Remain Domain-Local
Rule of thumb: centralize what must be shared for interoperability and trust; localize what enables speed and domain fit.
| Area | Must be centralized (enterprise-level) | Can be domain-local (bounded contexts) |
|---|---|---|
| Semantics | Core definitions + glossary; KPI definitions for enterprise reporting | Domain-specific concepts/metrics (explicitly mapped where needed) |
| Identifiers | Canonical IDs for core entities + mapping rules | Local IDs, with mappings to canonical IDs |
| Reference data | Ownership + lifecycle for shared code sets/statuses/hierarchies | Domain-only enumerations that don’t cross boundaries |
| Contracts | Standards for data/event contracts; versioning + deprecation rules | Implementation details and release cadence within compatibility rules |
| EDA schema governance | Schema registry policy + compatibility mode; mandatory event metadata | Payload evolution within compatibility constraints |
| Security & privacy | Classification, retention, masking, access policy-as-code | Domain roles mapped to enterprise policies |
| Quality & reliability | SLO framework; minimum observability requirements | Domain monitors, incident response, SLO commitments |
| Platform | Paved roads: templates, CI checks, lineage capture, catalog integration | Domain implementations if standards are met |
How to Make Data Mesh + EDA Work Without Recreating a Central Bottleneck
1) Adopt contracts for both datasets and events
Contracts specify schema and meaning, constraints, privacy classification, ownership, SLOs, and a deprecation policy. For events, treat schemas as APIs.
2) Automate governance (governance-as-code)
Replace manual reviews with CI/CD checks: metadata completeness, contract presence, compatibility checks, and policy enforcement.
3) Use a schema registry and enforce compatibility rules
Compatibility checks prevent accidental breaking changes and force producers to evolve responsibly.
4) Standardize event metadata
A consistent envelope (e.g., CloudEvents) improves routing, observability, and interoperability across producers/consumers.
5) Make lineage and enterprise data-flow mapping non-optional
In hybrid landscapes (legacy + microservices), lineage/catalog is the fastest path out of “data archaeology”—and the prerequisite for scalable ownership.
A Practical 90-Day Starting Point
If you need an actionable starting plan, the highest leverage steps typically look like this:
Weeks 1–4
- Publish a minimal glossary for core entities and KPIs used in enterprise reporting.
- Define canonical identifiers for 3–5 core entities (and mapping rules).
- Establish reference data ownership for shared code sets.
Weeks 5–8
- Introduce data/event contracts and “no contract, no publish.”
- Add schema registry checks for events (compatibility mode + CI gating).
- Start capturing lineage for critical pipelines and reports.
Weeks 9–12
- Define data reliability SLOs (freshness, completeness) for key data products.
- Roll out standard templates (“paved roads”) for publishing datasets/events.
- Make cross-domain escalation lightweight but real: semantic conflicts must resolve fast.
Conclusion: Modern Architecture Is Often a Governance Problem in Disguise
Data Mesh and EDA are not shortcuts around enterprise discipline. They scale only when discipline is built in:
- Domain ownership (accountability close to the source),
- Central semantic clarity (EDM, glossary, canonical identifiers),
- Contract-based interoperability (data products and event schemas),
- Automated governance (policy-as-code, CI/CD checks),
- Operational excellence (observability, lineage, SLOs).
Modern architectures don’t eliminate governance.
They make it non-optional.